2.1 Installing and Loading Necessary Packages
As part of the data processing, we first start with installing the required packages if they are not already installed and calling the libraries. The below chunk of code will handle all the necessary packages required without one needing to install manually. The required packages will only have to be mentioned in the ‘packages’ list. The purpose of requiring the below packages are:
tidyverse - Majority of the data cleaning function such as ‘read_csv’, ‘startWith’, ‘gsub’ etc all belong in this library.
DT - To display the data frame in an interactive manner to the user.
mgsub - This is similar to the use of ‘gsub’ but can specify more than 1 string pattern.
readxl, xlsx - To read “.xlxs” or “.xls” files and write into them
splitstackshape - The function ‘cSplit’ that is present in this package is used to split a string into multiple rows.
knitr - Used to display static dataframes in a proper way
packages = c('tidyverse','DT','mgsub','readxl','xlsx','splitstackshape','knitr')
for(p in packages){
if(!require(p, character.only = T)){
install.packages(p)
}
library(p, character.only = T)
}
2.2 Importing Provided Data
The data provided are a set of current and historical news reports, as well as resumes of numerous GAStech employees and email headers from two weeks of internal GAStech company email. The data in resumes folder has already been processed and is in the ‘EmployeeRecords.xlsx’ file. Therefore, we will be using that file directly.
| File/Folder Name | About |
|---|---|
| News Articles | Folder containing various newsgroups and news articles within them |
| resumes | Folder consisting of resumes of employees |
| EmployeeRecords.xlsx | Details on employees |
| email headers.csv | Email headers from two weeks |
Screen Shot of data folder is as below
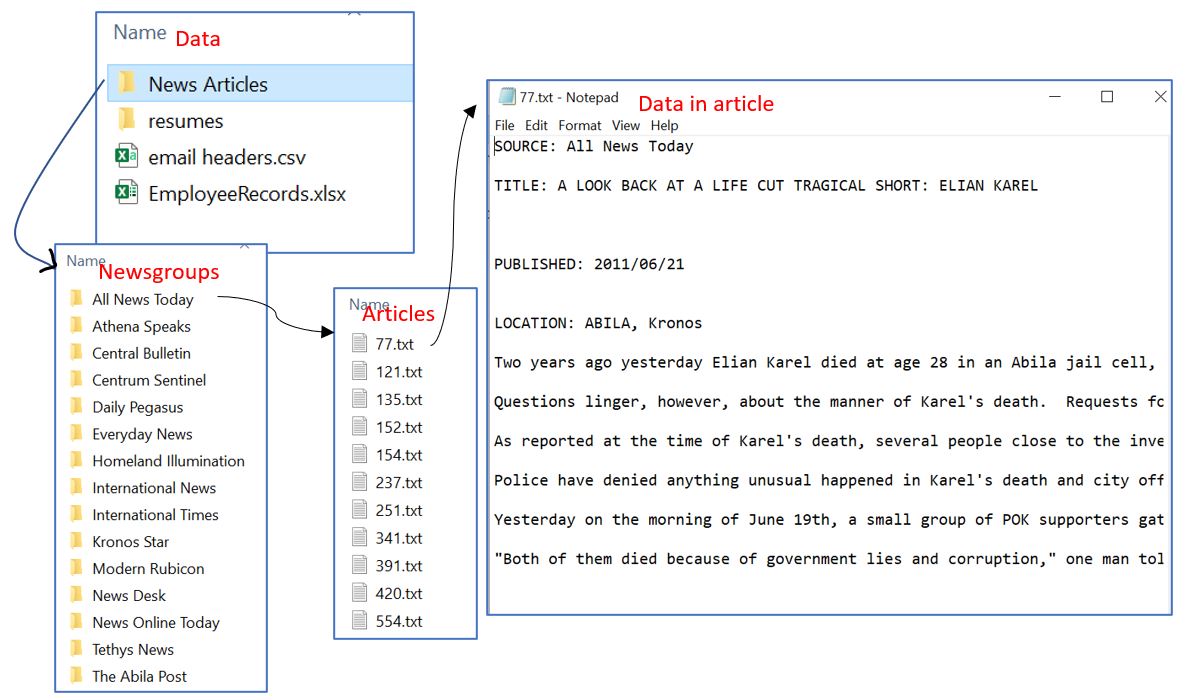
Importing News Articles
Since there are multiple files in various folders, we specify the root directory which is the “News Articles” and write a function to read all files from folder into a data frame instead of using a for loop which is slower. After reading all files, we will save all the data into a variable called ‘raw_text’.
#root folder directory
news="data/News Articles/"
#define a function to read all files from folder into a data frame
read_folder=function(infolder){
tibble(file=dir(infolder,full.names=TRUE))%>%
mutate(text=map(file,read_lines))%>%
transmute(id=basename(file),text) %>%
unnest(text)
}
#read data
raw_text=tibble(folder=
dir(news,
full.names=TRUE)) %>%
mutate(folder_out=map(folder,
read_folder)) %>%
unnest(cols=c(folder_out)) %>%
transmute(newsgroup=basename(folder),id,text)
Importing Email and Employee data
For the data already present in either a “.xlsx” or “.csv” file, we can use the existing functions “read_excel” and “read_csv” respectively. These functions will read the data in the files and output them as data frames. “read_excel” function can be used for not only “.xlsx” but also “.xls” files.
employee_data <- read_excel("data/EmployeeRecords.xlsx")
email_data <- read_csv("data/email headers.csv")
2.3 Processing News Articles
Below is how the raw_text datatable looks like. It is visible that the data is very dirty and there is a lot of processing that has to be done.
kable(head(raw_text,5))
| newsgroup | id | text |
|---|---|---|
| All News Today | 121.txt | SOURCE: All News Today |
| All News Today | 121.txt | |
| All News Today | 121.txt | TITLE: POK PROTESTS END IN ARRESTS |
| All News Today | 121.txt | |
| All News Today | 121.txt |
2.3.1 Initial Cleaning Steps
Lets start by deleting the text that are empty strings and also it is noticeable that text starting with “SOURCE” is of no additional use to us as the content is already available in column ‘newsgroup’. Also, lets maintain the ‘id’ column as a number and remove the ‘.txt’ extension..
#delete empty cells
row_numbers=which(raw_text$text %in% c(""," "))
raw_text=raw_text[-c(row_numbers),]
#remove .txt from id
raw_text$id=gsub(".txt","",raw_text$id)
#remove the SOURCE as it s already there as newsgroup
row_numbers=which(grepl("SOURCE:",raw_text$text,fixed=TRUE))
raw_text=raw_text[-c(row_numbers),]
head(raw_text,10)
# A tibble: 10 x 3
newsgroup id text
<chr> <chr> <chr>
1 All News Tod~ 121 "TITLE: POK PROTESTS END IN ARRESTS "
2 All News Tod~ 121 "PUBLISHED: 2005/04/06"
3 All News Tod~ 121 "LOCATION: ELODIS, Kronos "
4 All News Tod~ 121 "Fifteen members of the Protectors of Kronos (~
5 All News Tod~ 121 "When the federal police began arresting the P~
6 All News Tod~ 135 "TITLE: RALLY SCHEDULED IN SUPPORT OF INCREASE~
7 All News Tod~ 135 "PUBLISHED: 2012/04/09"
8 All News Tod~ 135 "LOCATION: ABILA, Kronos "
9 All News Tod~ 135 "Silvia Marek, leader of the Protectors of Kro~
10 All News Tod~ 135 "\"I'm calling for an end to the heinous corru~2.3.2 Processing Title
Instead of keeping all text in one column, it is better to have distinct columns for different contents. For example, there is a sub field starting with “TITLE” in the text column and it can be put into a new separate column. For this, we make use of two functions called ‘startsWith’ which checks if a string starts with the mentioned string and ‘gsub’ which replaces a string with another string.
raw_text$Title <-ifelse(startsWith(raw_text$text, "TITLE"),gsub("TITLE: ","",raw_text$text),"")
Do note that for text processing, one has to check the resultant datatable to see if there is any further modification required. In this case, after going through the data table, it was observed that file id 33 has misplaced text and this has to be separately handled as below. From the image below, we can see that the content in “Title”, “Published” and Author" are misplaced
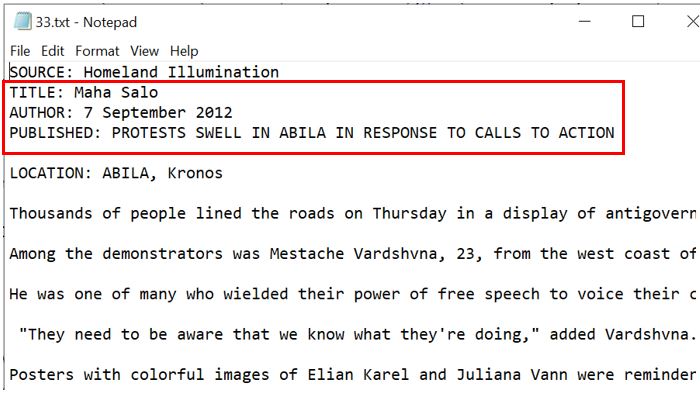
#after exploring the data, it appears that the content of file 33 is not proper.
#So there is a need to modify it separately
raw_text$Title=ifelse(raw_text$id=="33",
ifelse(startsWith(raw_text$text, "PUBLISHED"),
gsub("PUBLISHED: ","",raw_text$text),""),
raw_text$Title)
kable(head(raw_text,3))
| newsgroup | id | text | Title |
|---|---|---|---|
| All News Today | 121 | TITLE: POK PROTESTS END IN ARRESTS | POK PROTESTS END IN ARRESTS |
| All News Today | 121 | PUBLISHED: 2005/04/06 | |
| All News Today | 121 | LOCATION: ELODIS, Kronos |
Since only those records that have “TITLE” in their text column have the column Title populated, the below code will populate all records with Title using the id as a matching criteria. The function ‘unique’ is used to identify the unique values present in the datatable. The ‘which’ function returns the row numbers that meet the criteria. Function ‘match’ is used to obtain value from another dataframe based on the match condition. Lastly, we trim any spaces present at the start or end of the string. This is done using the function ‘str_trim’.
title_sub_dataframe=unique(raw_text[c("id","Title")])
row_numbers=which(title_sub_dataframe$Title=="")
title_sub_dataframe=title_sub_dataframe[-c(row_numbers),]
raw_text$Title=title_sub_dataframe$Title[match(raw_text$id,title_sub_dataframe$id)]
### trim space at start and end if there exists
raw_text$Title=str_trim(raw_text$Title, side = c("both"))
kable(head(raw_text,3))
| newsgroup | id | text | Title |
|---|---|---|---|
| All News Today | 121 | TITLE: POK PROTESTS END IN ARRESTS | POK PROTESTS END IN ARRESTS |
| All News Today | 121 | PUBLISHED: 2005/04/06 | POK PROTESTS END IN ARRESTS |
| All News Today | 121 | LOCATION: ELODIS, Kronos | POK PROTESTS END IN ARRESTS |
After looking through the dataframe again, noticed that there are a few titles which do the fit the context. One example of such titles is shown in the figure below. The mentioned two titles in the code chunck below are dates and do not fit the ‘Title’ column. Therefore, ‘ifelse’ statement can used to replace the mentioned titles to NA or else keep the title as it is. Such instance are why we have to check the data table after each step of processing the data.
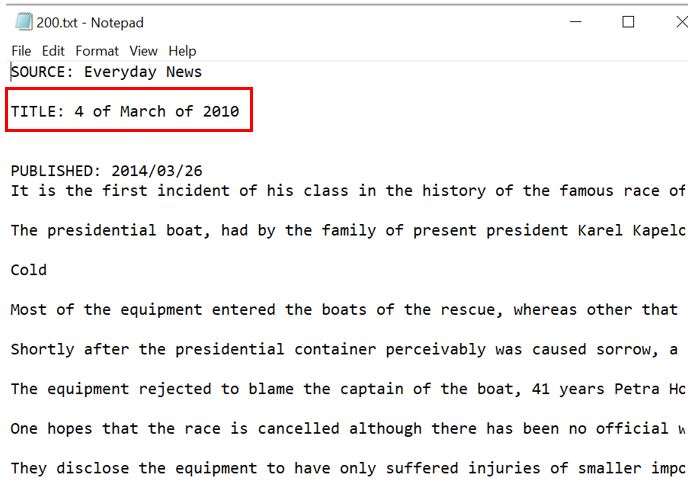
2.3.3 Processing Location
Having processed ‘Title’, lets move on to ‘Location’. Applying the similar logic used in Title’, run the below chunk of code to create a new column called ‘Location’. Here, ‘mgsub’ function was used and not ‘gsub’ because here we have to check for more than 1 string pattern and it cannot be done with ‘gsub’ hence, ‘mgsub’ function was used for the same purpose.
raw_text$Location <-ifelse(startsWith(raw_text$text, "LOCATION"),
mgsub(raw_text$text, c("LOCATION: ", "LOCATIONS: "),
c("", "")),"")
location_sub_dataframe=unique(raw_text[c("id","Location")])
row_numbers=which(location_sub_dataframe$Location=="")
location_sub_dataframe=location_sub_dataframe[-c(row_numbers),]
raw_text$Location=location_sub_dataframe$Location[match(raw_text$id,location_sub_dataframe$id)]
head(raw_text,10)
# A tibble: 10 x 5
newsgroup id text Title Location
<chr> <chr> <chr> <chr> <chr>
1 All News T~ 121 "TITLE: POK PROTES~ POK PROTESTS END ~ "ELODIS, ~
2 All News T~ 121 "PUBLISHED: 2005/0~ POK PROTESTS END ~ "ELODIS, ~
3 All News T~ 121 "LOCATION: ELODIS,~ POK PROTESTS END ~ "ELODIS, ~
4 All News T~ 121 "Fifteen members o~ POK PROTESTS END ~ "ELODIS, ~
5 All News T~ 121 "When the federal ~ POK PROTESTS END ~ "ELODIS, ~
6 All News T~ 135 "TITLE: RALLY SCHE~ RALLY SCHEDULED I~ "ABILA, K~
7 All News T~ 135 "PUBLISHED: 2012/0~ RALLY SCHEDULED I~ "ABILA, K~
8 All News T~ 135 "LOCATION: ABILA, ~ RALLY SCHEDULED I~ "ABILA, K~
9 All News T~ 135 "Silvia Marek, lea~ RALLY SCHEDULED I~ "ABILA, K~
10 All News T~ 135 "\"I'm calling for~ RALLY SCHEDULED I~ "ABILA, K~The unique locations existing in the datatable are:
unique(raw_text$Location)
[1] "ELODIS, Kronos "
[2] "ABILA, Kronos "
[3] NA
[4] "Abila, Kronos "
[5] "ABILA, Kronos"
[6] "TITLE: KRONOS POLICE ARREST BLOTTER "
[7] "TITLE: OF TEN YEARS "
[8] "ELODIS, Kronos"
[9] "TITLE: ARREST BLOTTER OF THE POLICE FORCE KRONOS "
[10] "CENTRUM, Tethys "
[11] "TITLE: ELODIS PUBLIC HEALTH FACT SHEET "
[12] "TITLE: GOVERNMENT STANDS UP ANTI"
[13] "TITLE: GRAND OPENING GASTECH"
[14] "TITLE: Abila police break up sit"
[15] "TITLE: Multi"
[16] "This is the first confirmation that today's events surrounding GAStech "
[17] "Kronos will add Tethys which anti"
[18] "TITLE: DRYING PAPER OF THE HALTING OF THE POLICE OF KRONOS "
[19] "DAVOS, Switzerland "
[20] "TITLE: The movement of the block"
[21] "This Article is the second of three" Based at the locations available, there is further processing that has to be done. After further exploring, it is noticeable that a few files have “LOCATION: TITLE:…” like the one show inth the image below. This does not make any sense as a Location and therefore, any text starting with “TITLE” under the column location can be replace with NA. Also, the syntax for a valid location is “City, Country” as seen from the unique values above, therefore, replacing all strings with no ‘,’ with NA will remove all other text present. Lastly, maintain the naming convention by keeping the city in capitals and country in a title format meaning only the first letter will be capital and others in lower case.
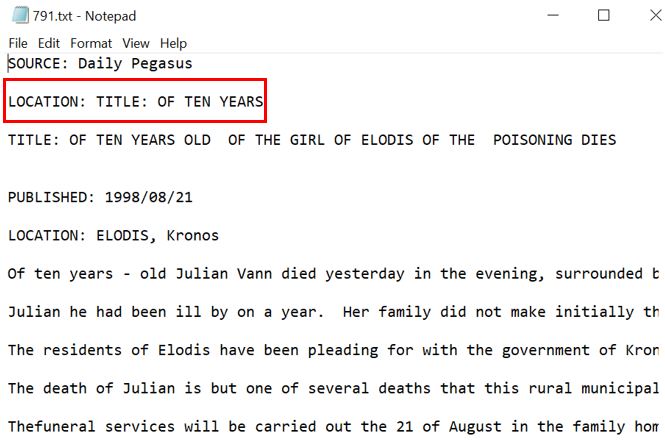
## need to further clean location
### replace everything that starts with TITLE to NA
raw_text$Location <-ifelse(startsWith(raw_text$Location, "TITLE"),NA,raw_text$Location)
### replace everything without ',' with NA
raw_text$Location <-ifelse(grepl(",",raw_text$Location,fixed=TRUE),raw_text$Location,NA)
### trim space at end
raw_text$Location=str_trim(raw_text$Location, side = c("both"))
### Standardize all names
raw_text$Location <-ifelse(!is.na(raw_text$Location),
paste0(toupper(substring(raw_text$Location,1,
gregexpr(pattern=',',
raw_text$Location)[[1]][1])),
substring(raw_text$Location,
gregexpr(pattern =',',
raw_text$Location)[[1]][1]+1,)),
raw_text$Location)
unique(raw_text$Location)
[1] "ELODIS, Kronos" "ABILA, Kronos" NA
[4] "CENTRUM, Tethys" "DAVOS, Switzerland"The location values now look clean and tidy.
2.3.4 Processing Published
Next, lets process the “Published” column. Applying the similar logic used in Title’ and ‘Location’, run the below chunk of code to create a new column called ‘Published’. Just like in ‘Title’, article number 33 has misplaced content therefore, it need to be handled separately.
raw_text$Published <-ifelse(startsWith(raw_text$text, "PUBLISHED") |
startsWith(raw_text$text, " PUBLISHED"),
mgsub(raw_text$text, c("PUBLISHED: ", " PUBLISHED: "),
c("", "")),
"")
#after exploring the data, it appears that the content of file 33 is not proper.
#So there is a need to modify it separately
raw_text$Published=ifelse(raw_text$id=="33",
ifelse(startsWith(raw_text$text, "AUTHOR"),
gsub("AUTHOR: ","",raw_text$text),""),
raw_text$Published)
published_sub_dataframe=unique(raw_text[c("id","Published")])
row_numbers=which(published_sub_dataframe$Published=="")
published_sub_dataframe=published_sub_dataframe[-c(row_numbers),]
raw_text$Published=published_sub_dataframe$Published[match(raw_text$id,published_sub_dataframe$id)]
### trim space at start and end if there exists
raw_text$Published=str_trim(raw_text$Published, side = c("both"))
kable(head(raw_text,3))
| newsgroup | id | text | Title | Location | Published |
|---|---|---|---|---|---|
| All News Today | 121 | TITLE: POK PROTESTS END IN ARRESTS | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005/04/06 |
| All News Today | 121 | PUBLISHED: 2005/04/06 | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005/04/06 |
| All News Today | 121 | LOCATION: ELODIS, Kronos | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005/04/06 |
The unique published dates existing in the datatable are:
unique(raw_text$Published)
[1] "2005/04/06" "2012/04/09"
[3] "1993/02/02" "Petrus Gerhard"
[5] "1998/05/15" "2004/05/29"
[7] "2013/06/21" "2001/03/22"
[9] "1998/11/15" "2009/06/20"
[11] "2007/03/21" "1999/07/08"
[13] "1998/05/16" "2009/03/12"
[15] "2012/06/20" "2014/01/19"
[17] "2012/09/08" "2011/06/21"
[19] "By Haneson Ngohebo" "2014/01/20"
[21] "2009/02/21" "2009/06/21"
[23] "1997/10/17" "2013/12/17"
[25] "2011/11/23" "2000/10/04"
[27] "2000/08/18" "2009/03/14"
[29] "2005/09/26" "2010/06/15"
[31] "2011/05/15" "2007/04/11"
[33] "1998/11/17" "2010/10/04"
[35] "2012/03/10" "2010/06/21"
[37] "2011/07/29" "1997/04/24"
[39] "2012/08/24" "2005/09/25"
[41] "2011/07/28" "1997/04/23"
[43] "1997/10/16" "2012/08/23"
[45] "2010/10/03" "2010/06/14"
[47] "1998/11/16" "2000/10/02"
[49] "2009/02/19" "2000/08/17"
[51] "2009/03/13" "20 January 2014"
[53] "21 January 2014" "2012/11/11"
[55] "2002/05/27" "2001/09/02"
[57] "1998/05/17" "2004/05/31"
[59] "1998/03/21" "2001/03/23"
[61] "2009/03/09" "2014/03/26"
[63] "2012/06/22" "1998/04/27"
[65] "2013/06/22" "2000/06/01"
[67] "1993/02/04" "2005/04/07"
[69] "2012/04/10" "1998/08/21"
[71] "2013/02/24" "1999/11/16"
[73] "2009/02/23" "1982/10/03"
[75] "21 October 2013" "2007/03/19"
[77] "2012/06/21" "2009/06/23"
[79] "2014/01/21" "1984/05/05"
[81] "2013/11/13" "2012/02/22"
[83] "2013/02/09" "19 January 2014"
[85] "22 March 2001" "20 June 2011"
[87] "20 June 2012" "05 April 2005"
[89] "31 May 2000" "20 June 2013"
[91] "19 August 1998" "12 March 2009"
[93] "25 May 2002" "7 September 2012"
[95] "15 May 1998" "9 April 2012"
[97] "14 November 1998" "7 July 1999"
[99] "25 April 1998" "31 August 2001"
[101] "2 February 1993" "20 March 2007"
[103] "19 March 1998" "19 June 2009"
[105] "29 May 2004" "7 March 2009"
[107] "19 June 2010" "2001/08/31"
[109] "1993/01/19" "2013/12/16"
[111] "2013/06/20" "1995/10/11"
[113] "1995/11/21" "2001/03/18"
[115] "2009/02/18" "1996/03/14"
[117] "1999/07/04" "22 February 2013"
[119] "21 January 2014 1405" "20 February 2012"
[121] "22 June 2009" "4 October 1982"
[123] "14 November 1999" "12 November 2013"
[125] "22 February 2009" "18 March 2007"
[127] "2 October 1982" "7 February 2013"
[129] "3 May 1984" "18 February 2009"
[131] "15 December 2013" "17 March 2001"
[133] "30 August 2001" "14 June 2001"
[135] "7 March 2012" "18 January 1998"
[137] "13 March 1996" "21 November 1995"
[139] "3 July 1999" "20 June 2010"
[141] "10 October 1995" "21 June 2012"
[143] "27 July 2011" "20 June 2009"
[145] "9 November 1998" "18 January 1993"
[147] "12 March 1993" "6 April 2005"
[149] "2007/04/12" "2000/10/03"
[151] "1997/04/25" "2013/12/18"
[153] "2010/06/22" "2011/11/24"
[155] "12 November 2012" "1999/11/15"
[157] "1996/07/08" "2013/02/08"
[159] "2009/06/22" "2012/08/22"
[161] "1997/10/15" "17 December 2013"
[163] "1984/05/04" "1998/08/20"
[165] "5 February 2012" "1998/01/19"
[167] "2010/06/19" "2013/02/22"
[169] "1995/03/30" "1993/03/13"
[171] "2003/05/17" "1992/12/12"
[173] "2000/08/15" "2009/03/08"
[175] "21 June 2009" "2013/09/03"
[177] "1998/11/10" "2001/09/01"
[179] "1994/09/24" "2012/03/09"
[181] "12 August 2009" "1998/11/14"
[183] "2013/10/22" "1993/02/03"
[185] "2009/05/16" "1993/09/20"
[187] "2002/05/25" "1999/02/19"
[189] "1994/02/18" "2001/06/15"
[191] "2004/05/30" "2000/01/15"
[193] "2012/03/08" "2012/02/21"
[195] "30 June 2013" "1995/11/22"
[197] "2 October 2010" "8 March 2012"
[199] "15 October 1997" "24 September 2005"
[201] "2 October 2000" "22 August 2012"
[203] "14 May 2011" "15 November 1998"
[205] "16 August 2000" "22 November 2011"
[207] "10 April 2007" "23 April 1997"
[209] "19 February 2009" "13June 2010"
[211] "16 December 2013" "2010/03/05"
[213] "2009/02/20" "2011/05/16"
[215] "2000/01/17" "1994/09/25"
[217] "2009/02/22" "2000/08/16"
[219] "1999/02/20" "2013/09/04"
[221] "2010/12/18" "2003/05/19"
[223] "1995/10/12" "1993/09/21"
[225] "2009/05/17" "1992/12/13"
[227] "1995/04/01" "2012/06/23"
[229] "2001/06/16" "1995/11/23"
[231] "1996/03/15" "2005/04/08"
[233] "2011/06/22" "1998/01/20"
[235] "2000/01/16" "1995/03/31"
[237] "2002/05/26" "1999/07/09"
[239] "2007/03/22" "2001/03/24"
[241] "1998/03/20" "2012/11/12"
[243] "1993/01/20" "1993/03/14"
[245] "2010/12/19" "1996/07/09"
[247] "30 March 1995" "15 May 2009"
[249] "15 January 2000" "13 November 1998"
[251] "7 July 1996" "15 August 2000"
[253] "18 February 1999" "17 May 2003"
[255] "11 December 1992" "19 September 1993"
[257] "17 February 1994" "2 September 2013"
[259] "23 September 1994" "1998/04/26"
[261] "2012/04/11" "2000/06/02"
[263] "2003/05/18" "1993/09/19"
[265] "1982/10/04" "2007/03/20"
[267] "October 21, 2013" "1984/05/03"
[269] "1982/10/02" "1999/11/14"
[271] "1999/07/05" The date is of many different formats and some are even in text. All of these are processed in the below chunk of code. We first convert all the data that is not in a date format to date.
Next, convert all dates in “21 January 2014” format to “Y/M/D” and for this, we make use of Regular Expression. The ‘as.Date’ function can be used to convert the text into date and then formatting it again using ‘format’ function to obtain “Y/M/D” format.
## filtering published dates in "21 January 2014" format and converting them to Y/M/D format
dates_to_format=str_extract(raw_text$Published, "^[0-9]{1,2}\\D[a-zA-Z]+\\D[0-9]{4}")
dates_to_format=unique(dates_to_format)
dates_to_format=dates_to_format[!is.na(dates_to_format)]
sub_dates=unique(raw_text[c("id","Published")]) %>% filter(Published %in% dates_to_format)
sub_dates$Published=as.Date(sub_dates$Published,format="%d %B %Y")
sub_dates$Published=format(sub_dates$Published,"%Y/%m/%d")
raw_text$subdates=sub_dates$Published[match(raw_text$id,sub_dates$id)]
Since there are a few texts present in the Published column, after looking into the files of those id’s, it was noticeable that the date was in the next line as shown in the figure below and therefore, for these texts, the published date should be taken from the next immediate row.
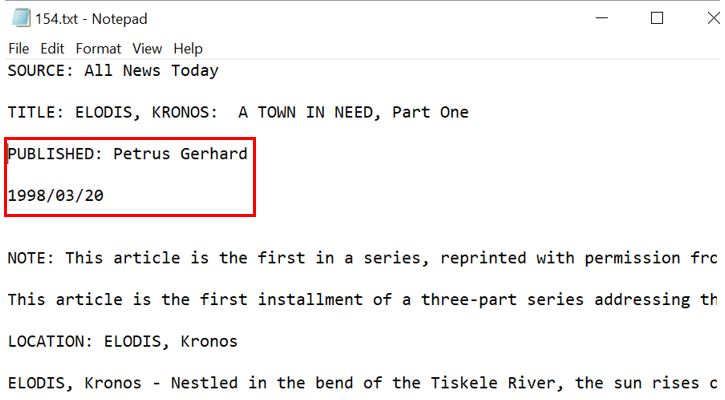
## words improper
dates_to_format=str_extract(raw_text$Published, c("Petrus Gerhard","By Haneson Ngohebo"))
dates_to_format=unique(dates_to_format)
dates_to_format=dates_to_format[!is.na(dates_to_format)]
sub_dates2=raw_text %>% filter(Published %in% dates_to_format)
row_numbers=which(startsWith(sub_dates2$text, "PUBLISHED"))
row_numbers=row_numbers+1
subset=sub_dates2[row_numbers,]
sub_dates2$Published=subset$text[match(sub_dates2$id,subset$id)]
raw_text$subdates2=sub_dates2$Published[match(raw_text$id,sub_dates2$id)]
We then update the ‘Published’ column with the modified dates using the code below.
raw_text$Published=ifelse(!is.na(raw_text$subdates),raw_text$subdates,raw_text$Published)
raw_text$Published=ifelse(!is.na(raw_text$subdates2),raw_text$subdates2,raw_text$Published)
unique(raw_text$Published)
[1] "2005/04/06" "2012/04/09" "1993/02/02"
[4] "1998/03/20" "1998/05/15" "2004/05/29"
[7] "2013/06/21" "2001/03/22" "1998/11/15"
[10] "2009/06/20" "2007/03/21" "1999/07/08"
[13] "1998/05/16" "2009/03/12" "2012/06/20"
[16] "2014/01/19" "2012/09/08" "2011/06/21"
[19] "2014/01/20" "2009/02/21" "2009/06/21"
[22] "1997/10/17" "2013/12/17" "2011/11/23"
[25] "2000/10/04" "2000/08/18" "2009/03/14"
[28] "2005/09/26" "2010/06/15" "2011/05/15"
[31] "2007/04/11" "1998/11/17" "2010/10/04"
[34] "2012/03/10" "2010/06/21" "2011/07/29"
[37] "1997/04/24" "2012/08/24" "2005/09/25"
[40] "2011/07/28" "1997/04/23" "1997/10/16"
[43] "2012/08/23" "2010/10/03" "2010/06/14"
[46] "1998/11/16" "2000/10/02" "2009/02/19"
[49] "2000/08/17" "2009/03/13" "2014/01/21"
[52] "2012/11/11" "2002/05/27" "2001/09/02"
[55] "1998/05/17" "2004/05/31" "1998/03/21"
[58] "2001/03/23" "2009/03/09" "2014/03/26"
[61] "2012/06/22" "1998/04/27" "2013/06/22"
[64] "2000/06/01" "1993/02/04" "2005/04/07"
[67] "2012/04/10" "1998/08/21" "2013/02/24"
[70] "1999/11/16" "2009/02/23" "1982/10/03"
[73] "2013/10/21" "2007/03/19" "2012/06/21"
[76] "2009/06/23" "1984/05/05" "2013/11/13"
[79] "2012/02/22" "2013/02/09" "2011/06/20"
[82] "2005/04/05" "2000/05/31" "2013/06/20"
[85] "1998/08/19" "2002/05/25" "2012/09/07"
[88] "1998/11/14" "1999/07/07" "1998/04/25"
[91] "2001/08/31" "2 February 1993" "2007/03/20"
[94] "1998/03/19" "2009/06/19" "2009/03/07"
[97] "2010/06/19" "1993/01/19" "2013/12/16"
[100] "1995/10/11" "1995/11/21" "2001/03/18"
[103] "2009/02/18" "1996/03/14" "1999/07/04"
[106] "2013/02/22" "2012/02/20" "2009/06/22"
[109] "1982/10/04" "1999/11/14" "2013/11/12"
[112] "2009/02/22" "2007/03/18" "1982/10/02"
[115] "2013/02/07" "1984/05/03" "2013/12/15"
[118] "2001/03/17" "2001/08/30" "2001/06/14"
[121] "2012/03/07" "1998/01/18" "1996/03/13"
[124] "1999/07/03" "2010/06/20" "1995/10/10"
[127] "2011/07/27" "1998/11/09" "1993/01/18"
[130] "1993/03/12" "2007/04/12" "2000/10/03"
[133] "1997/04/25" "2013/12/18" "2010/06/22"
[136] "2011/11/24" "2012/11/12" "1999/11/15"
[139] "1996/07/08" "2013/02/08" "2012/08/22"
[142] "1997/10/15" "1984/05/04" "1998/08/20"
[145] "2012/02/05" "1998/01/19" "1995/03/30"
[148] "1993/03/13" "2003/05/17" "1992/12/12"
[151] "1998/04/26" "2000/08/15" "2009/03/08"
[154] "2013/09/03" "1998/11/10" "2001/09/01"
[157] "1994/09/24" "2012/03/09" "2009/08/12"
[160] "2013/10/22" "1993/02/03" "2009/05/16"
[163] "1993/09/20" "1999/02/19" "1994/02/18"
[166] "2001/06/15" "2004/05/30" "2000/01/15"
[169] "2012/03/08" "2012/02/21" "2013/06/30"
[172] "1995/11/22" "20 January 2014" "21 January 2014"
[175] "2010/10/02" "2005/09/24" "2011/05/14"
[178] "2000/08/16" "2011/11/22" "2007/04/10"
[181] "2010/06/13" "2010/03/05" "2009/02/20"
[184] "2011/05/16" "2000/01/17" "1994/09/25"
[187] "1999/02/20" "2013/09/04" "2010/12/18"
[190] "2003/05/19" "1995/10/12" "1993/09/21"
[193] "2009/05/17" "1992/12/13" "1995/04/01"
[196] "2012/06/23" "2001/06/16" "1995/11/23"
[199] "1996/03/15" "2005/04/08" "2011/06/22"
[202] "1998/01/20" "2000/01/16" "1995/03/31"
[205] "2002/05/26" "1999/07/09" "2007/03/22"
[208] "2001/03/24" "1993/01/20" "1993/03/14"
[211] "2010/12/19" "1996/07/09" "2009/05/15"
[214] "1998/11/13" "1996/07/07" "1999/02/18"
[217] "1992/12/11" "1993/09/19" "1994/02/17"
[220] "2013/09/02" "1994/09/23" "2012/04/11"
[223] "2000/06/02" "2003/05/18" "1999/07/05" There seem to be still other formats of dates present. The below code will process them into the date formats like other dates.
dates_to_format=str_extract(raw_text$Published, "^[0-9]{1,2}\\D[a-zA-Z]+\\D{1,2}[0-9]{4}")
dates_to_format=unique(dates_to_format)
dates_to_format=dates_to_format[!is.na(dates_to_format)]
sub_dates3=unique(raw_text[c("id","Published")]) %>% filter(Published %in% dates_to_format)
sub_dates3$Published=as.Date(sub_dates3$Published,format="%d %B %Y")
sub_dates3$Published=format(sub_dates3$Published,"%Y/%m/%d")
raw_text$subdates3=sub_dates3$Published[match(raw_text$id,sub_dates3$id)]
Now we will update the Publish column again and remove all other temporary column we create as part of processing. Also, since all the published dates are in the date format, we will chnage the datatype from character to date for the ’Published" column.
raw_text$Published=ifelse(!is.na(raw_text$subdates3),raw_text$subdates3,raw_text$Published)
raw_text=raw_text[,!(names(raw_text) %in% c("subdates","subdates2","subdates3"))]
raw_text$Published=as.Date(raw_text$Published,format="%Y/%m/%d")
kable(head(raw_text,3))
| newsgroup | id | text | Title | Location | Published |
|---|---|---|---|---|---|
| All News Today | 121 | TITLE: POK PROTESTS END IN ARRESTS | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005-04-06 |
| All News Today | 121 | PUBLISHED: 2005/04/06 | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005-04-06 |
| All News Today | 121 | LOCATION: ELODIS, Kronos | POK PROTESTS END IN ARRESTS | ELODIS, Kronos | 2005-04-06 |
2.3.5 Processing Content
Since we have extracted “TITLE”, “LOCATION” and ’PUBLISHED" from the text column and created separate columns for them ,we can exclude all the records that have the “text” column consisting of these content.
# removing text with TITLE:, LOCATION:, PUBLISHED:
row_numbers1=which(startsWith(raw_text$text, "TITLE"))
row_numbers2=which(startsWith(raw_text$text, "PUBLISHED"))
row_numbers3=which(startsWith(raw_text$text, " PUBLISHED"))
row_numbers4=which(startsWith(raw_text$text, "LOCATION"))
row_numbers5=which(startsWith(raw_text$text, "AUTHOR"))
raw_text=raw_text[-c(row_numbers1,row_numbers2,row_numbers3,row_numbers4,row_numbers5),]
raw_text
# A tibble: 3,015 x 6
newsgroup id text Title Location Published
<chr> <chr> <chr> <chr> <chr> <date>
1 All News ~ 121 "Fifteen membe~ POK PROTESTS ~ ELODIS,~ 2005-04-06
2 All News ~ 121 "When the fede~ POK PROTESTS ~ ELODIS,~ 2005-04-06
3 All News ~ 135 "Silvia Marek,~ RALLY SCHEDUL~ ABILA, ~ 2012-04-09
4 All News ~ 135 "\"I'm calling~ RALLY SCHEDUL~ ABILA, ~ 2012-04-09
5 All News ~ 152 "In a glitzy p~ LACK OF DETAI~ ABILA, ~ 1993-02-02
6 All News ~ 154 "1998/03/20" ELODIS, KRONO~ ELODIS,~ 1998-03-20
7 All News ~ 154 "NOTE: This ar~ ELODIS, KRONO~ ELODIS,~ 1998-03-20
8 All News ~ 154 "This article ~ ELODIS, KRONO~ ELODIS,~ 1998-03-20
9 All News ~ 154 "ELODIS, Krono~ ELODIS, KRONO~ ELODIS,~ 1998-03-20
10 All News ~ 154 "Two weeks pri~ ELODIS, KRONO~ ELODIS,~ 1998-03-20
# ... with 3,005 more rowsGoing through the text column, it was visible that there are dates present in some records and this is due to some files having Published date in the next line which was discussed under “Processing Published” category. These dates are present in “yyyy/mm/dd” format or “date month year” format. The below regular expressions were used to detect those patterns in the text column.
raw_text1=str_extract(raw_text$text,c("^[0-9]{1,2}\\D[a-zA-Z]+\\D[0-9]{4}","^[0-9]{4}\\D[0-9]{1,2}\\D[0-9]{1,2}"))
raw_text1=unique(raw_text1)
raw_text1=raw_text1[!is.na(raw_text1)]
raw_text1[6] ="1998/05/15"
raw_text1[7] ="17 January 1995"
row_numbers6=which(raw_text$text %in% raw_text1)
raw_text=raw_text[-c(row_numbers6),]
Now, we have to combine all the records with the same id. After processing, we now will have 845 records that reflect the 845 files that we have and each record consists of the “newsgroup”, “id”, “Title”, “Location”, “Published” and “Content”.
content=raw_text %>%
group_by(id) %>%
summarise_all(funs(toString(na.omit(.))))
raw_text=raw_text[,!(names(raw_text) %in% c("text"))]
raw_text$Content=content$text[match(raw_text$id,content$id)]
cleaned_text=unique(raw_text)
cleaned_text
# A tibble: 845 x 6
newsgroup id Title Location Published Content
<chr> <chr> <chr> <chr> <date> <chr>
1 All News ~ 121 POK PROTESTS ~ ELODIS,~ 2005-04-06 "Fifteen membe~
2 All News ~ 135 RALLY SCHEDUL~ ABILA, ~ 2012-04-09 "Silvia Marek,~
3 All News ~ 152 LACK OF DETAI~ ABILA, ~ 1993-02-02 "In a glitzy p~
4 All News ~ 154 ELODIS, KRONO~ ELODIS,~ 1998-03-20 "NOTE: This ar~
5 All News ~ 237 ELODIS, KRONO~ <NA> 1998-05-15 "NOTE: This ar~
6 All News ~ 251 ELODIS PUBLIC~ ELODIS,~ 2004-05-29 "The Elodis Co~
7 All News ~ 341 WHO BRINGS A ~ ABILA, ~ 2013-06-21 "ABILA, Kronos~
8 All News ~ 391 TAX MEASURE D~ ABILA, ~ 2001-03-22 "A measure to ~
9 All News ~ 420 POK REPRESENT~ ABILA, ~ 1998-11-15 "Representativ~
10 All News ~ 554 ELIAN KAREL D~ ABILA, ~ 2009-06-20 "Elian Karel, ~
# ... with 835 more rows2.4 Processing Email and Employee Data
2.4.1 Processing Email Data
Considering that the data is based on email, we can make use of the networking graph for visualization and for that purpose, we will need the data to be in the “source” and “target” format. The email_data dataframe currently is very raw and needs to be processed to the required format.
kable(head(email_data,2))
| From | To | Date | Subject |
|---|---|---|---|
| Varja.Lagos@gastech.com.kronos | Varja.Lagos@gastech.com.kronos, Hennie.Osvaldo@gastech.com.kronos, Loreto.Bodrogi@gastech.com.kronos, Inga.Ferro@gastech.com.kronos | 1/6/2014 10:28 | Patrol schedule changes |
| Brand.Tempestad@gastech.com.kronos | Birgitta.Frente@gastech.com.kronos, Lars.Azada@gastech.com.kronos, Felix.Balas@gastech.com.kronos | 1/6/2014 10:35 | Wellhead flow rate data |
The “To” column has various email id’s that are seperated by a ‘,’. We first need to split all the id’s by ‘,’ and then use the ‘cSplit’ function to split all the emails in “To” into multiple rows.
# break on , in "To"
email_data_clean <- cSplit(email_data,splitCols= "To", sep=",", direction="long")
glimpse(email_data_clean)
Rows: 8,990
Columns: 4
$ From <chr> "Varja.Lagos@gastech.com.kronos", "Varja.Lagos@gaste~
$ To <fct> Varja.Lagos@gastech.com.kronos, Hennie.Osvaldo@gaste~
$ Date <chr> "1/6/2014 10:28", "1/6/2014 10:28", "1/6/2014 10:28"~
$ Subject <chr> "Patrol schedule changes", "Patrol schedule changes"~Next, we shall remove the email id’s where the “From” and “To” are the same. This is to ensure that when be plot the networking graph, we will not have the same user who send an email to himself.
Since both the date and the time are displayed in the same column, we shall separate these two and change their datatype accordingly.
# separating time and date
email_data_clean <- cSplit(email_data_clean, splitCols="Date",sep= " ")
#changing type of date 1,2
email_data_clean$Date_1=as.Date(email_data_clean$Date_1,format="%m/%d/%Y")
email_data_clean$Date_2=format(strptime(email_data_clean$Date_2, format="%H:%M"), format = "%H:%M")
glimpse(email_data_clean)
Rows: 8,185
Columns: 5
$ From <chr> "Varja.Lagos@gastech.com.kronos", "Varja.Lagos@gaste~
$ To <fct> Hennie.Osvaldo@gastech.com.kronos, Loreto.Bodrogi@ga~
$ Subject <chr> "Patrol schedule changes", "Patrol schedule changes"~
$ Date_1 <date> 2014-01-06, 2014-01-06, 2014-01-06, 2014-01-06, 201~
$ Date_2 <chr> "10:28", "10:28", "10:28", "10:35", "10:35", "10:35"~The whole email id is not required. Therefore, we will remove everything after ‘@’ from both the “From” and “To” columns. For this, we use the regular expression "@.*" which specifies that everything from “@” and we use “gsub” function to replace that with and empty string.
Rename the column names into meaningful names using the “colnames” function.
2.4.2 Processing Employee Data
Lets have a look at hoe the employee data is like.
glimpse(employee_data)
Rows: 54
Columns: 18
$ LastName <chr> "Bramar", "Ribera", "Pantanal", "~
$ FirstName <chr> "Mat", "Anda", "Rachel", "Linda",~
$ BirthDate <dttm> 1981-12-19, 1975-11-17, 1984-08-~
$ BirthCountry <chr> "Tethys", "Tethys", "Tethys", "Te~
$ Gender <chr> "Male", "Female", "Female", "Fema~
$ CitizenshipCountry <chr> "Tethys", "Tethys", "Tethys", "Te~
$ CitizenshipBasis <chr> "BirthNation", "BirthNation", "Bi~
$ CitizenshipStartDate <dttm> 1981-12-19, 1975-11-17, 1984-08-~
$ PassportCountry <chr> "Tethys", "Tethys", "Tethys", "Te~
$ PassportIssueDate <dttm> 2007-12-12, 2009-06-15, 2013-06-~
$ PassportExpirationDate <dttm> 2017-12-11, 2019-06-14, 2023-06-~
$ CurrentEmploymentType <chr> "Administration", "Administration~
$ CurrentEmploymentTitle <chr> "Assistant to CEO", "Assistant to~
$ CurrentEmploymentStartDate <dttm> 2005-07-01, 2009-10-30, 2013-10-~
$ EmailAddress <chr> "Mat.Bramar@gastech.com.kronos", ~
$ MilitaryServiceBranch <chr> NA, NA, NA, NA, "ArmedForcesOfKro~
$ MilitaryDischargeType <chr> NA, NA, NA, NA, "HonorableDischar~
$ MilitaryDischargeDate <dttm> NA, NA, NA, NA, 1984-10-01, 2001~Remove unnecessary columns.
Since there are no ID’s allotted for the employees, we can create a new column called “id” and populate this column with ID numbers starting from 1 to the number of rows present in the data frame. Since the “Source.Label” and “Target.Label” in the email_data are in firstname.lastname format, we will make use of the “FirstName” , “LastName” columns present in employee_data and use the “paste0” function to join then together with a “.” between them. Pay special attention to ‘Ruscella.Mies Haber’ as there exists two words in her last name so replace the space with a “.”.
Now that we have two clean data frame, we must map them together using the “match” function based.
Remove the “.” from all names to enhanse the redability to the user.
## remove "." from labels to make it look better
email_data_clean$Source.Label=sub("[.]"," ",email_data_clean$Source.Label)
email_data_clean$Target.Label=gsub("[.]"," ",email_data_clean$Target.Label)
employee_data$FullName=gsub("[.]"," ",employee_data$FullName)
glimpse(email_data_clean)
Rows: 8,185
Columns: 7
$ Source.Label <chr> "Varja Lagos", "Varja Lagos", "Varja Lagos", "B~
$ Target.Label <chr> "Hennie Osvaldo", "Loreto Bodrogi", "Inga Ferro~
$ Subject <chr> "Patrol schedule changes", "Patrol schedule cha~
$ SentDate <date> 2014-01-06, 2014-01-06, 2014-01-06, 2014-01-06~
$ SentTime <chr> "10:28", "10:28", "10:28", "10:35", "10:35", "1~
$ Source <int> 45, 45, 45, 13, 13, 13, 41, 40, 39, 39, 39, 39,~
$ Target <int> 48, 52, 54, 17, 14, 15, 40, 41, 3, 14, 15, 9, 1~Categorizing email based on work related and non work related. Go through the data to identify the subject text for non work related emails. Using that text, we can categorize the records.
email_data_clean$Subject=tolower(email_data_clean$Subject)
nonWork=c('birthdays','plants','night','concert','coffee','sick','dress','post','funy',
'lunch','babysitting','politics','cute','parking','vacation','funny','missing',
'volunteers','nearby','club','investment','found','flowers',
'defenders','battlestations','article','ha ha','media','retirement')
for (i in (1:nrow(email_data_clean))){
email_data_clean$MainSubject[i] <-ifelse(ifelse(any(str_detect(email_data_clean$Subject[i],
nonWork))==TRUE,TRUE,FALSE),
"Non-work related","Work related")
}
glimpse(email_data_clean)
Rows: 8,185
Columns: 8
$ Source.Label <chr> "Varja Lagos", "Varja Lagos", "Varja Lagos", "B~
$ Target.Label <chr> "Hennie Osvaldo", "Loreto Bodrogi", "Inga Ferro~
$ Subject <chr> "patrol schedule changes", "patrol schedule cha~
$ SentDate <date> 2014-01-06, 2014-01-06, 2014-01-06, 2014-01-06~
$ SentTime <chr> "10:28", "10:28", "10:28", "10:35", "10:35", "1~
$ Source <int> 45, 45, 45, 13, 13, 13, 41, 40, 39, 39, 39, 39,~
$ Target <int> 48, 52, 54, 17, 14, 15, 40, 41, 3, 14, 15, 9, 1~
$ MainSubject <chr> "Work related", "Work related", "Work related",~2.5 Storing Clean Data into Files
Having cleaned all the data we have, we can now store this cleaned data into files so that it can be used for visualization. When writing into files, we need to set “row.names=FALSE” we avoid writing the row numbers into the first column.
Note: The dataframes we obtained through the processing steps are now clean and these frames can further be modified according to the need of visualization.